Tarjan 算法寻找有向图的强连通分量
在图论中,一个有向图被成为是强连通的(strongly connected)当且仅当每一对不相同结点 u 和 v 间既存在从 u 到 v 的路径也存在从 v 到 u 的路径。有向图的极大强连通子图(这里指点数极大)被称为强连通分量(strongly connected component)。
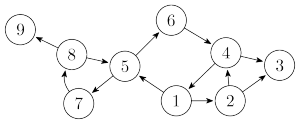
比如说这个有向图中,点 $1, 2, 4, 5, 6, 7, 8$ 和相应边组成的子图就是一个强连通分量,另外点 $3, 9$ 单独构成强连通分量。
Tarjan 算法是由 Robert Tarjan 提出的用于寻找有向图的强连通分量的算法。它可以在$\mathcal O(|V|+|E|)$的时间内得出结果。
Tarjan 算法主要是利用 DFS 来寻找强连通分量的。在介绍该算法之前,我们先来介绍一下搜索树。先前那个有向图的搜索树是这样的:
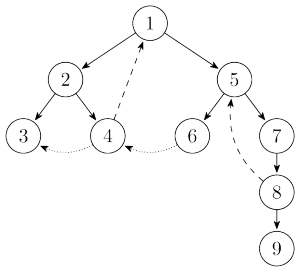
有向图的搜索树主要有 4 种边(这张图只有 3 种),其中用实线画出来的是树边(tree edge),每次搜索找到一个还没有访问过的结点的时候就形成了一条树边。用长虚线画出来的是反祖边(back edge),也被叫做回边。用短虚线画出来的是横叉边(cross edge),它主要是在搜索的时候遇到了一个已经访问过的结点,但是这个结点并不是当前节点的祖先时形成的。除此之外,像从结点1到结点6这样的边叫做前向边(forward edge),它是在搜索的时候遇到子树中的结点的时候形成的。
现在我们来看看在 DFS 的过程中强连通分量有什么性质。
很重要的一点是如果结点 u 是某个强连通分量在搜索树中遇到的第一个结点(这通常被称为这个强连通分量的根),那么这个强连通分量的其余结点肯定是在搜索树中以 u 为根的子树中。如果有个结点 v 在该强连通分量中但是不在以 u 为根的子树中,那么 u 到 v 的路径中肯定有一条离开子树的边。但是这样的边只可能是横叉边或者反祖边,然而这两条边都要求指向的结点已经被访问过了,这就和 u 是第一个访问的结点矛盾了。
Tarjan 算法主要是在 DFS 的过程中维护了一些信息:dfn、low 和一个栈。
- 栈里的元素表示的是当前已经访问过但是没有被归类到任一强连通分量的结点。
- dfn[u] 表示结点 u 在 DFS 中第一次搜索到的次序,通常被叫做时间戳。
- low[u] 稍微有些复杂,它表示从 u 或者以 u 为根的子树中的结点,再通过一条反祖边或者横叉边可以到达的时间戳最小的结点 v 的时间戳,并且要求 v 有一些额外的性质:v 还要能够到达 u。显然通过反祖边到达的结点 v 满足 low 的性质,但是通过横叉边到达的却不一定。
可以证明,结点 u 是某个强连通分量的根等价于 dfn[u] 和 low[u] 相等。简单可以理解成当它们相等的时候就不可能从 u 通过子树再经过其它时间戳比它小的结点回到 u。
当通过 u 搜索到一个新的节点 v 的时候可以有多种情况:
-
结点 u 通过树边到达结点 v
\[\begin{equation*} \text{low}[u] = \min(\text{low}[u], \text{low}[v]) \end{equation*}\] -
结点 u 通过反祖边到达结点 v,或者通过横叉边到达结点 v 并且满足 low 定义中 v 的性质
\[\begin{equation*} \text{low}[u] = \min(\text{low}[u], \text{dfn}[v]) \end{equation*}\]
在 tarjan 算法进行 DFS 的过程中,每离开一个结点,我们就判断一下 low 是否小于 dfn,如果是,那么着个结点可以到达它先前的结点再通过那个结点回到它,肯定不是强连通分量的根。如果 dfn 和 low 相等,那么就不断退栈直到当前结点为止,这些结点就属于一个强连通分量。
至于如何更新 low,关键就在于第二种情况,当通过反祖边或者横叉边走到一个结点的时候,只需要判断这个结点是否在栈中,如果在就用它的 low 值更新当前节点的 low 值,否则就不更新。因为如果不在栈中这个结点就已经确定在某个强连通分量中了,不可能回到 u。
现在我们对着先前的图模拟一次。结点内的标号就是 dfn 值,结点边上的标号是表示 low 值,当前所在的结点用灰色表示。

首先从第一个结点开始进行搜索,最初 low[1] = 1。此时栈里的结点是 $1$。
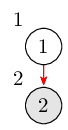
然后到达第二个结点,同时也初始化 low[2] = 2。此时栈里的结点是 $1, 2$。
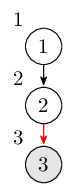
类似地,到达第三个结点,同时也初始化 low[3] = 3。此时栈里的结点是 $1, 2, 3$。
此时结点 3 没有其余边可以继续进行搜索了,我们需要离开它了,因为发现 dfn[3] = low[3],所以结点 3 是一个强连通分量的根,出栈直到结点 3 为止,得到刚好只有一个结点 3 的强连通分量。此时栈里的结点是 $1, 2$。
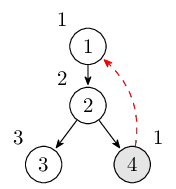
从结点 3 返回后到结点 2,而后进入结点 4,从结点 4 可以到达结点 1,但是结点 1 已经访问过了,并且是通过反祖边,更新 low[4] 的值。此时栈里的结点是 $1, 2, 4$。
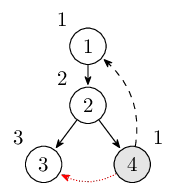
继续从结点 4 还可以通过横叉边到达结点 3,但是结点 3 并不在栈中(也就是结点 3 并没有路径到达结点 4),不做任何改动。此时栈里的结点是 $1, 2, 4$。
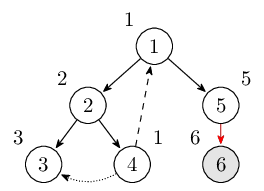
接着一直搜索直到结点 6。此时栈里的结点是 $1, 2, 4, 5, 6$。
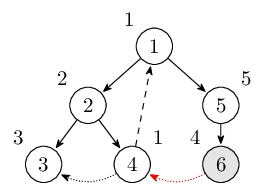
从结点 6 出发可以通过横叉边到达结点 4,因为它已经访问过而且还在栈中,更新 low[6]。此时栈里的结点是 $1, 2, 4, 5, 6$。

接着回退到结点 5,使用结点 6 的值更新 low[5]。此时栈里的结点是 $1, 2, 4, 5, 6$。
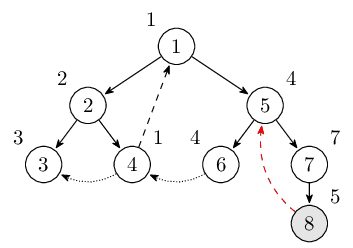
从结点 5 出发经过结点 7 后到达结点 8。遇到反祖边回到结点 5 更新 low[8]。此时栈里的结点是 $1, 2, 4, 5, 6, 7, 8$。
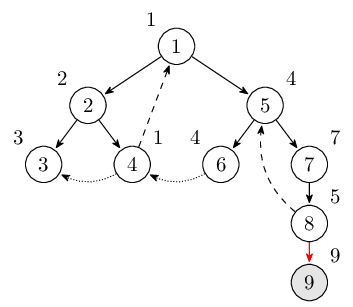
继续到达结点 9。此时栈里的结点是 $1, 2, 4, 5, 6, 7, 8, 9$。
离开时发现 dfn[9] = low[9]。找到强连通分量,出栈。此时栈里的结点是 $1, 2, 4, 5, 6, 7, 8$。

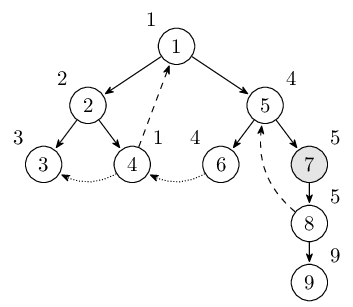
回到结点 8,此时 low[8] < dfn[8],不做处理继续回退。
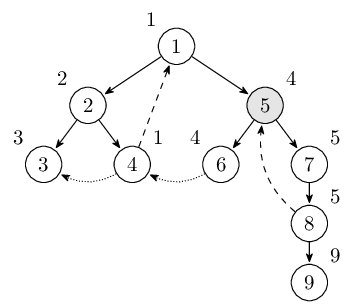
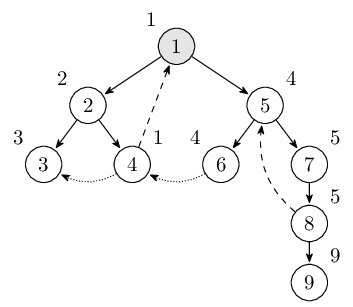
直到回到结点 1 的时候,low[1] = dfn[1]。此时栈里的结点是 $1, 2, 4, 5, 6, 7, 8$。一直退栈直到遇见 1,找到强连通分量 $1, 2, 4, 5, 6, 7, 8$。
/* 寻找有向图强连通分量的tarjan算法
* dfn_index 表示的就是时间戳
* scc_index 表示强连通分量的个数
* scc[u] 表示结点u属于那一个强连通分量
* on_stack[u] 表示结点u是否仍然在栈中
* stack 和 st 分辨表示栈和栈顶位置 */
void tarjan(int u)
{
dfn[u] = low[u] = ++dfn_index;
on_stack[u] = 1; stack[st++] = u;
for(int k = head[u]; k; k = next[k])
{
int v = point[k];
if(!dfn[v])
{
// 树边的情况
tarjan(v);
if(low[v] < low[u])
low[u] = low[v];
} else if(on_stack[v] && dfn[v] < low[u]) {
// 横叉边或者反祖边的情况
low[u] = dfn[v];
}
}
if(low[u] == dfn[u])
{
++scc_index, tmp = 0;
while(tmp != u)
{
tmp = stack[--st];
scc[tmp] = scc_index;
on_stack[tmp] = 0;
}
}
}-
2017-05-03 14:55:42yqkqknct (#1)圖中的點 2 的 low 應該是 1 吧?
-
2017-05-03 16:35:46miskcoo (#2) reply to没错是1
-
2017-10-17 19:55:32Nolin (#3)结点 u 通过反祖边到达结点 v,或者通过横叉边到达结点 v 并且满足 low 定义中 v 的性质 low[u]=min(low[u],dfn[v]) 为什么不能用low[v]呢,能举个例子吗
-
2017-11-16 13:43:36liangzexian (#4)请问这些图是怎么做出来的?
-
2018-01-11 12:49:07P6174 (#5)求 LaTeX 源码
-
2018-10-10 13:16:46daqin (#6) reply tohttps://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm 伪代码最后一段解释了。 另外talk页面对这个问题也有不少讨论,感觉原因可以分两块,一个主要是符合原作对lowlink的定义,另一个是 > If w is a parent of v in the DFS tree, its lowlink' is not finalized, and could still change. This means you can not just define v.lowlink' as the smallest index v can reach, because that is not necessarily true. 不过改用low[v]得到的scc结果应该是一样的。
-
2019-01-24 22:10:00Jaanai (#7) reply to如果是low[v]的话,比如low[6],他走一条横叉边最早可以到4,dfn[4]=4,所以用dfn,如果用low的话,low[4]=1,代表4节点一条返祖边最早可以到1,如果low[6]=1,那么指6->4->1这条路径,和low的定义违背了,因为这条路有两条边,而low只能是一条边,所以要用dfn,否则表示两条边